Today, it is hard to imagine writing an application without accessing some form of storage at runtime. This includes not only writing application code but also deployment scripts, which often need to access configuration files, which are also a type of storage in a sense. When developing applications to solve real-world business problems, connecting to databases, external APIs, caching systems, or other forms of storage is practically unavoidable. It’s no surprise, then, that Domain-Driven Design (DDD) includes patterns like the Repository pattern to address these needs. While DDD didn’t invent the Repository pattern, it added more clarity and context to its usage.
The Anti-Corruption Layer #
Domain-Driven Design (DDD) is a principle that can be applied to various aspects of software development and in different parts of a software system. However, its primary focus is on the domain layer, which is where our core business logic resides. While the Repository pattern is responsible for handling technical details related to external data storage and doesn’t inherently belong to the business logic, there are situations where we need to access the Repository from within the domain layer.
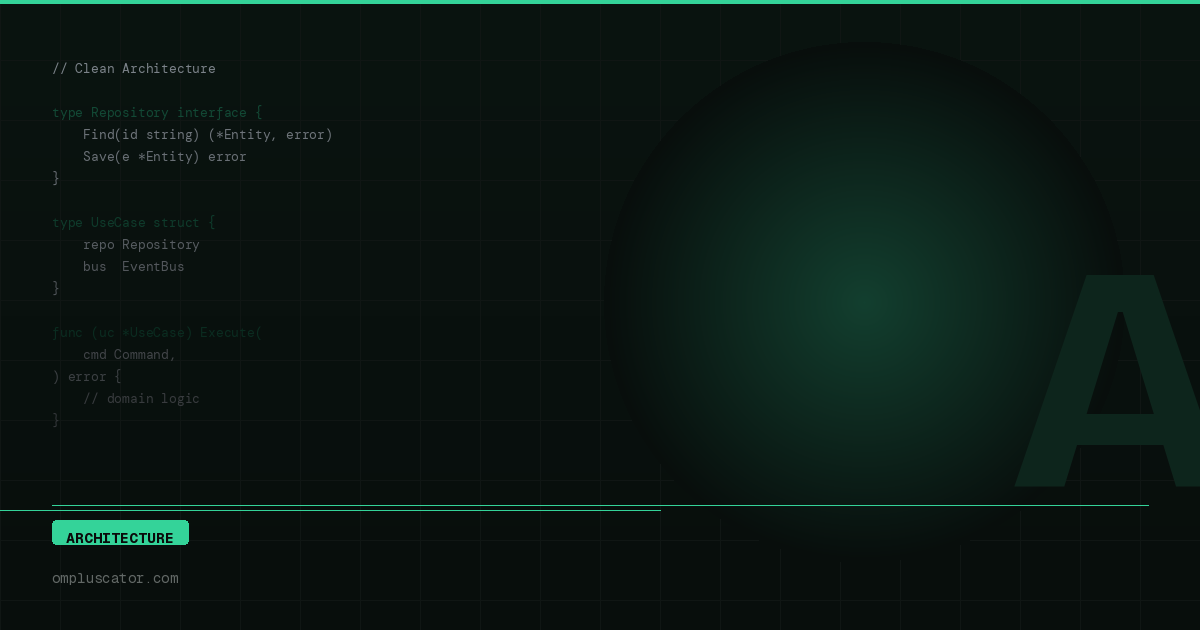
Since the domain layer is typically isolated from other layers and doesn’t directly communicate with them, we define the Repository within the domain layer, but we define it as an interface. This interface serves as an abstraction that allows us to interact with external data storage without tightly coupling the domain layer to specific technical details or implementations.
A Simple Repository example
type Customer struct {
ID uuid.UUID
//
// some fields
//
}
type Customers []Customer
type CustomerRepository interface {
GetCustomer(ctx context.Context, ID uuid.UUID) (*Customer, error)
SearchCustomers(ctx context.Context, specification CustomerSpecification) (Customers, int, error)
SaveCustomer(ctx context.Context, customer Customer) (*Customer, error)
UpdateCustomer(ctx context.Context, customer Customer) (*Customer, error)
DeleteCustomer(ctx context.Context, ID uuid.UUID) (*Customer, error)
}The interface that defines method signatures within our domain layer is referred to as a “Contract.” In the example
provided, we have a simple Contract interface that specifies CRUD (Create, Read, Update, Delete) methods. By defining
the Repository as this interface, we can use it throughout the domain layer. The Repository interface always expects
and returns our Entities, such as Customer and Customers (collections with specific methods attached to them,
as defined in Go).
It’s important to note that the Entity Customer doesn’t contain any information about the underlying storage type,
such as Go tags for defining JSON structures, Gorm columns, or anything of that
sort. This kind of low-level storage configuration is typically handled in the infrastructure layer.
The Domain Layer
type CustomerRepository interface {
GetCustomer(ctx context.Context, ID uuid.UUID) (*Customer, error)
SearchCustomers(ctx context.Context, specification CustomerSpecification) (Customers, int, error)
SaveCustomer(ctx context.Context, customer Customer) (*Customer, error)
UpdateCustomer(ctx context.Context, customer Customer) (*Customer, error)
DeleteCustomer(ctx context.Context, ID uuid.UUID) (*Customer, error)
}DAO on the Infrastructure Layer
type CustomerGorm struct {
ID uint `gorm:"primaryKey;column:id"`
UUID string `gorm:"uniqueIndex;column:uuid"`
//
// some fields
//
}
func (c CustomerGorm) ToEntity() (model.Customer, error) {
parsed, err := uuid.Parse(c.UUID)
if err != nil {
return Customer{}, err
}
return model.Customer{
ID: parsed,
//
// some fields
//
}, nil
}Repository on the Infrastructure Layer
type CustomerRepository struct {
connection *gorm.DB
}
func (r *CustomerRepository) GetCustomer(ctx context.Context, ID uuid.UUID) (*model.Customer, error) {
var row CustomerGorm
err := r.connection.WithContext(ctx).Where("uuid = ?", ID).First(&row).Error
if err != nil {
return nil, err
}
customer, err := row.ToEntity()
if err != nil {
return nil, err
}
return &customer, nil
}
//
// other methods
//In the example above, you can observe a snippet of CustomerRepository implementation. Internally, it utilizes
Gorm for smoother integration, but you can also use pure SQL queries if preferred. Lately, I’ve been using the
Ent library extensively. In this example, you encounter two distinct structures: Customer
and CustomerGorm.
The first structure serves as an Entity, intended for housing our business logic, domain invariants, and rules. It remains oblivious to the underlying database. The second structure functions as a Data Access Objects (DAO, responsible solely for mapping data to and from the storage system. This structure doesn’t have any other role aside from facilitating the mapping of database data to our Entity.
The separation of these two structures is a fundamental aspect of using the Repository pattern as an Anti-Corruption layer in our application. It ensures that technical details related to table structure don’t contaminate our business logic. What are the implications of this approach? Firstly, it necessitates the management of two types of structures: one for business logic and one for storage. Additionally, a third structure is often introduced, which serves as a Data Transfer Objects (DTO for our API. This approach introduces complexity into our application and entails the creation of multiple mapping functions, as exemplified in the code snippet below. It’s essential to thoroughly test such methods to prevent common copy-paste errors.
Entities on the Domain Layer
type Customer struct {
ID uuid.UUID
Person *Person
Company *Company
Address Address
}
type Person struct {
SSN string
FirstName string
LastName string
Birthday Birthday
}
type Birthday time.Time
type Company struct {
Name string
RegistrationNumber string
RegistrationDate time.Time
}
type Address struct {
Street string
Number string
Postcode string
City string
}DAOs on the Infrastructure Layer
type CustomerGorm struct {
ID uint `gorm:"primaryKey;column:id"`
UUID string `gorm:"uniqueIndex;column:id"`
PersonID uint `gorm:"column:person_id"`
Person *PersonGorm `gorm:"foreignKey:PersonID"`
CompanyID uint `gorm:"column:company_id"`
Company *CompanyGorm `gorm:"foreignKey:CompanyID"`
Street string `gorm:"column:street"`
Number string `gorm:"column:number"`
Postcode string `gorm:"column:postcode"`
City string `gorm:"column:city"`
}
func (c CustomerGorm) ToEntity() (model.Customer, error) {
parsed, err := uuid.Parse(c.UUID)
if err != nil {
return model.Customer{}, err
}
return model.Customer{
ID: parsed,
Person: c.Person.ToEntity(),
Company: c.Company.ToEntity(),
Address: Address{
Street: c.Street,
Number: c.Number,
Postcode: c.Postcode,
City: c.City,
},
}, nil
}
type PersonGorm struct {
ID uint `gorm:"primaryKey;column:id"`
SSN string `gorm:"uniqueIndex;column:ssn"`
FirstName string `gorm:"column:first_name"`
LastName string `gorm:"column:last_name"`
Birthday time.Time `gorm:"column:birthday"`
}
func (p *PersonGorm) ToEntity() *model.Person {
if p == nil {
return nil
}
return &model.Person{
SSN: p.SSN,
FirstName: p.FirstName,
LastName: p.LastName,
Birthday: Birthday(p.Birthday),
}
}
type CompanyGorm struct {
ID uint `gorm:"primaryKey;column:id"`
Name string `gorm:"column:name"`
RegistrationNumber string `gorm:"column:registration_number"`
RegistrationDate time.Time `gorm:"column:registration_date"`
}
func (c *CompanyGorm) ToEntity() *model.Company {
if c == nil {
return nil
}
return &model.Company{
Name: c.Name,
RegistrationNumber: c.RegistrationNumber,
RegistrationDate: c.RegistrationDate,
}
}
func NewRow(customer model.Customer) CustomerGorm {
var person *PersonGorm
if customer.Person != nil {
person = &PersonGorm{
SSN: customer.Person.SSN,
FirstName: customer.Person.FirstName,
LastName: customer.Person.LastName,
Birthday: time.Time(customer.Person.Birthday),
}
}
var company *CompanyGorm
if customer.Company != nil {
company = &CompanyGorm{
Name: customer.Company.Name,
RegistrationNumber: customer.Company.RegistrationNumber,
RegistrationDate: customer.Company.RegistrationDate,
}
}
return CustomerGorm{
UUID: uuid.NewString(),
Person: person,
Company: company,
Street: customer.Address.Street,
Number: customer.Address.Number,
Postcode: customer.Address.Postcode,
City: customer.Address.City,
}
}However, despite the additional maintenance involved, this approach adds significant value to our codebase. It allows us to represent our Entities within the domain layer in a manner that best encapsulates our business logic. We are not restricted by the storage solution we employ. For instance, we can use one type of identifier within our business logic (such as UUID) and a different one for the database (unsigned integer). This flexibility extends to any data we wish to use for the database and business logic.
When modifications are made in either of these layers, it is likely that we will need to make corresponding adjustments in mapping functions, while the rest of the layer remains untouched (or at least minimally impacted). We can opt to switch to a different database system like MongoDB or Cassandra, or even switch to an external API, all without affecting our domain layer.
Persistence #
The Repository primarily serves for querying purposes and integrates seamlessly with another DDD pattern known as Specification, as you may have observed in the examples. While it can be used without Specification, it often simplifies our workflow. The second key function of the Repository is Persistence. It encompasses the logic for persisting our data in the underlying storage, ensuring its permanence, facilitating updates, and even enabling deletion when necessary.
Generate UUID
type CustomerRepository struct {
connection *gorm.DB
}
func (r *CustomerRepository) SaveCustomer(ctx context.Context, customer Customer) (*Customer, error) {
row := NewRow(customer)
err := r.connection.WithContext(ctx).Save(&row).Error
if err != nil {
return nil, err
}
customer, err = row.ToEntity()
if err != nil {
return nil, err
}
return &customer, nil
}In some scenarios, we opt for generating unique identifiers within an application. In such cases, the Repository is the appropriate location for this task. In the provided example, you can observe that we generate a new UUID before creating the database record. We can employ a similar approach with integers if we aim to avoid relying on auto-incrementing database keys. Regardless of the method chosen, when we prefer not to depend on database-generated keys, it is advisable to create identifiers within the Repository.
Database Transactions
type CustomerRepository struct {
connection *gorm.DB
}
func (r *CustomerRepository) CreateCustomer(ctx context.Context, customer Customer) (*Customer, error) {
tx := r.connection.Begin()
defer func() {
if r := recover(); r != nil {
tx.Rollback()
}
}()
if err := tx.Error; err != nil {
return nil, err
}
//
// some code
//
var total int64
var err error
if customer.Person != nil {
err = tx.Model(PersonGorm{}).Where("ssn = ?", customer.Person.SSN).Count(&total).Error
} else if customer.Person != nil {
err = tx.Model(CompanyGorm{}).Where("registration_number = ?", customer.Person.SSN).Count(&total).Error
}
if err != nil {
tx.Rollback()
return nil, err
} else if total > 0 {
tx.Rollback()
return nil, errors.New("there is already such record in DB")
}
//
// some code
//
err = tx.Save(&row).Error
if err != nil {
tx.Rollback()
return nil, err
}
err = tx.Commit().Error
if err != nil {
tx.Rollback()
return nil, err
}
customer := row.ToEntity()
return &customer, nil
}Another important function of the Repository is managing transactions. When we need to persist data and perform multiple queries that operate on the same extensive set of tables, it is a suitable situation to establish a transaction, which should be managed within the Repository.
In the provided example, we are verifying the uniqueness of a Person or Company. If they already exist, we
return an error. All of these operations can be defined as part of a single transaction, and if any part of it fails,
we can roll it back. In this context, the Repository serves as an ideal location for such code. It’s worth noting
that, in the future, we might simplify our inserts to the extent that transactions are no longer required.
In that case, we won’t need to change the Repository’s contract, only the internal code.
Types of Repositories #
It is a mistake to think that we should use the Repository pattern exclusively for databases. While we frequently use it with databases since they are the primary choice for storage, alternative storage options have gained popularity today. As previously mentioned, we can utilize MongoDB or Cassandra as alternatives. Repositories can also be employed to manage our cache, where Redis, for instance, would be a suitable choice. Repositories can even be applied to REST APIs or configuration files when necessary.
Redis Repository
type CustomerRepository struct {
client *redis.Client
}
func (r *CustomerRepository) GetCustomer(ctx context.Context, ID uuid.UUID) (*Customer, error) {
data, err := r.client.Get(ctx, fmt.Sprintf("user-%s", ID.String())).Result()
if err != nil {
return nil, err
}
var row CustomerJSON
err = json.Unmarshal([]byte(data), &row)
if err != nil {
return nil, err
}
customer := row.ToEntity()
return &customer, nil
}REST API Repository
type CustomerRepository struct {
client *http.Client
baseUrl string
}
func (r *CustomerRepository) GetCustomer(ctx context.Context, ID uuid.UUID) (*Customer, error) {
resp, err := r.client.Get(path.Join(r.baseUrl, "users", ID.String()))
if err != nil {
return nil, err
}
data, err := ioutil.ReadAll(resp.Body)
if err != nil {
return nil, err
}
defer resp.Body.Close()
var row CustomerJSON
err = json.Unmarshal(data, &row)
if err != nil {
return nil, err
}
customer := row.ToEntity()
return &customer, nil
}Now we can truly appreciate the advantage of separating our business logic from technical details. By maintaining the same interface for our Repository, our domain layer remains unchanged. However, as our application expands, we may find that MySQL is no longer the ideal solution for our distributed application. In the event of a migration, we can transition without concern for how it will impact our business logic, as long as we maintain consistent interfaces.
Therefore, your Repository Contract should always revolve around your business logic, while your Repository implementation can use internal structures that can later be mapped to Entities.
Conclusion #
The Repository is a well-established pattern responsible for querying and persisting data in the underlying storage. It serves as the primary point for Anti-Corruption within our application. We define it as a Contract within the domain layer and house the actual implementation within the infrastructure layer. It is where we generate application-specific identifiers and manage transactions.